You might have been wondering: “Neil, what on Earth have you been doing for the past year? You’re always up at the weirdest hours and can’t seem to carry on normal conversations anymore!” Well, out today is a paper on one of the projects that’s eaten up several of those months, and about 5,000 years of CPU time: Investigating the Performance of an Adiabatic Quantum Optimization Processor.
It’s been in the works for years, with Geordie working to get the ball rolling and keep it rolling on the necessary Quantum Monte Carlo (QMC) simulations. Firas Hamze, Kamran Karimi, and I worked full-time for months to solve dozens of undocumented issues that came up in pre-processing, processing, post-processing, and managing such large-scale simulations on thousands of volunteers’ computers, and Mohammad Amin filled in some critical missing pieces of theory needed to get actual times for a quantum processor (as opposed to dimensionless, time-like quantities).
I’d like to summarize here some of what goes into a round of our simulations and some of the issues that crop up.
0. Before Getting Started
There are some major items needed before sending off any simulations over BOINC for our gracious volunteers to help us out. Probably the most obvious (so much that it’s easy to miss) is that we need something to be simulated. In our case, the objective was to simulate a very low temperature quantum processor (0.00075 degrees above absolute zero, about 27 times colder than the actual chips) solving a particular class of random NP-hard problems very slowly, and gather enough data from the simulation to predict the required time (known as the “adiabatic time”) to get a 63.2% success rate (i.e.  ) with such a processor. We called these problems “UH-1”, short for “Ultra Hard 1”, since we noticed that they were much more difficult than expected for IBM’s CPLEX, a standard commercial optimization program.
) with such a processor. We called these problems “UH-1”, short for “Ultra Hard 1”, since we noticed that they were much more difficult than expected for IBM’s CPLEX, a standard commercial optimization program.
The big question then is, how exactly do you simulate that? Well, after pages of derivations, it works out that you can find all of the information you need to upper-bound the adiabatic time using a QMC method known as the “Suzuki-Trotter decomposition”, or “Time-evolving block decimation”, which are basically just fancy words for “whole lot of copies linked together that you shake up”. More specifically:

…or something like that, I can’t remember if that’s the exact equation off the top of my head; it’s posted on my wall at work. Edit: Updated; I think it’s the right one now. Anyway, in order to make use of these concepts, we need a simulation program, it needs to be correct, and it can’t take the age of the universe to get back to us.
Also, in order to make this simulated processor a reasonable analogue of a real processor, we needed the real processor to be characterized. Since we didn’t need to simulate any real dynamics or noise in the processor, just static properties, we only needed the relevant energy scales throughout a computation and the layout of the chip.

Plot of Single-Qubit Kinetic (Tunnelling) Energy (A) and Potential Energy Scale (B) over a Computation
Last, and definitely not least, 5,000 years of CPU time doesn’t just fall out of the sky. We had to build up a community of volunteers interested in helping us on BOINC and make sure our app plays nicely with their computers. They’re doing us a huge service, so the last thing we want is to be a burden. To put things in perspective, I checked how much it’d cost to have done the same using rented server time on Amazon EC2, and it worked out to be around $4M to $5M, money we simply don’t have.
1. Pre-processing
One thing that we struggled with for ages was making sure that if we tell it to simulate something, it’s actually simulating that instead of it being in the process of heading toward simulating that so slowly that it never actually starts simulating the right thing. That’s a very cryptic was of saying “it’s even hard to figure out where it should start”.
One part of the solution to this is to simply let it simulate for a while without looking at it, hoping that it’s heading toward a good starting location. If you wait infinitely long, it will end up at a good location on average, but we don’t have that kind of time. We used the fact that near the end of the computation, a successful computation will have the system near the correct solution to the problem, and farther from the end of the computation, the simulation can get into a rough approximation of the right distribution in a reasonable amount of time (a few minutes).
However, accurately sampling near a point in the computation where the simulation should be representing a superposition of two sets of states that are far apart from each other, e.g. when the gap in energy between the lowest two energy states is small, exactly the points we want to examine, isn’t easy. If your simulation happens to fall into one of the two sets of states, (and usually one of the two is much easier to fall into than the other), it could take a very long time to randomly walk over to the other set, meaning that the simulation might only sample from one of the two, giving completely bogus results.
In order to get completely reliable results, we need to let the simulation make larger leaps… in a very controlled manner. This is accomplished by having many copies of the system, each at a different point in the computation, able to swap with each other. Carefully placing many more copies around these critical points where long distances need to be traversed is what Firas’ “Robust Parameter Selection” algorithm is all about. It’s an improvement on an algorithm by a collaborator, Helmut Katzgraber, modified to handle even these very bad cases. It’s still not perfect, since there are countless diabolical cases that can crop up, but with about a week of pre-processing on a half-dozen machines, it set up the bulk of the simulations in a round just fine.
2. Processing
A bunch of issues cropped up in the simulation’s main crunching, and a few of them require an intimate understanding of the theory behind it just to realize what to check. One of them was a “free” parameter we hadn’t realized actually significantly impacted the accuracy of the simulation. As it turns out, at one end of its possible range, almost any problem you give it to simulate will appear to be a trivial problem, whereas at the other end, it gives a very accurate simulation… but takes forever to simulate. We had originally had it set to some value about halfway in between, where it was still quite inaccurate, but enough problems still appeared non-trivial that we didn’t clue in that something was wrong. We happened to re-run a round of the simulations with a different value, and got drastically different results… curses!
So, in the end, we had to more than quadruple the size of our simulations to get accurate data, and to verify that the accuracy had roughly converged, we also ran a bunch of very slow simulations (about 4x as long again) of the smaller problems with 4x less error.
With all of this expansion in the simulation size, it’s a good thing we’d improved the performance of the app so much, or we’d simply have been sunk. The following plot sums up some performance improvements, on top of improvements in the thread balancing, for the main crunching part of the app (which is now down to only about 34% of the time, so it’s no longer the bottleneck).

Main performance results from Importance of Explicit Vectorization for CPU and GPU Software Performance
3. Post-processing
I can’t fully express the pain of trying to sift through hundreds of thousands of huge output files trying to find ways of automatically identifying which ones represent bogus data (e.g. transmitted to/from a volunteers’ computer incorrectly, memory/disk corruption, spurious emergent behaviour in the random number generators, etc.) Every output value has to be suspect. There are a whole bunch of output values that are known to be exactly 1.0, and in the application, it’s numerically impossible for them to become any other value than 1.0. Quite possibly the only reason these values are output at all is that in something like 1 in 500 output files (or more), one or more of these values is not 1.0. Even if they’re 0.9999999 or 1.0000001, either some sort of memory or disk access was corrupted, or the CPU was computing simple operations incorrectly, or a user fiddled with the output data, etc.
Note that I have strong evidence that user tampering does not account for a majority of those errors, and not just because it would take a lot of effort and would get caught by my overly-suspicious post-processing checks.
Some other issues in post-processing included the combination and interpretation of extremely rough data. It wasn’t just sufficient to handle noisy data, but even mediocre post-processing required estimation of the expected amount of noise on the data returned from the simulations. That only took a few pages of scratch, but handling the dozens of special ways in which the noise can manifest itself took a few months off my lifespan. Looking at the data as a human being with a brain, it’s usually so blatantly obvious where the noise kicks in, but trying to describe it for a computer to identify takes a lot of “patience”… actually, I don’t even need the air quotes, ’cause it takes a few hours to run the post-processing code and see if it worked or not.
A word of warning on the emergent behaviour in random number generators comment above, a negligibly small but non-zero probability can very easily accidentally become a 1 in 4,294,967,296 probability, which normally wouldn’t be an issue, but in huge simulations like these can cause maybe 1 in 200 output files to have a clearly unreasonable event occur that will throw off all results they’re used in. That and random number generators may randomly happen to have the same seeds if you’re not careful.
Having a good way of visualizing the results was also critical in finding and understanding these issues.
Conclusion
This has been a heck of a challenge over the past year, and I’m glad the paper on it is finally out there, showing that the median adiabatic time is really negligible for many small problem instances. There are much longer times that are more worthwhile worrying about in the mean time, e.g. milliseconds spent waiting for a chip to cool down after sending it a problem.
There are more exciting challenges going on with the Iterative QUANtum Algorithms (IQUANA) app, which uses results from one round of simulations to determine what happens on the next round… people don’t usually measure the time for one iteration of an algorithm in weeks, but this is an exception. 🙂
I can’t wait until the other big paper to be out soon is finally out. That one took a solid 6 months mixed in there.
Posted in D-Wave, Optimization, Programming


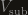 that diagonalize a 2×2 matrix, namely
that diagonalize a 2×2 matrix, namely![M_{\rm sub} = \left[\begin{array}{cc} M_{ii} & M_{ij} \\ M_{ji} & M_{jj}\end{array}\right]](https://s0.wp.com/latex.php?latex=M_%7B%5Crm+sub%7D+%3D+%5Cleft%5B%5Cbegin%7Barray%7D%7Bcc%7D+M_%7Bii%7D+%26+M_%7Bij%7D+%5C%5C+M_%7Bji%7D+%26+M_%7Bjj%7D%5Cend%7Barray%7D%5Cright%5D&bg=161410&fg=999999&s=0&c=20201002)
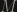 is the matrix we’re trying to diagonalize, and
is the matrix we’re trying to diagonalize, and 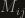 is the element we’re trying to eliminate. If
is the element we’re trying to eliminate. If  are real, and
are real, and  . However, I won’t assume that
. However, I won’t assume that  , where
, where  is upper triangular and the eigenvalues of
is upper triangular and the eigenvalues of  . In the non-Hermitian case, it doesn’t give the eigenvectors, but those can be more easily computed afterward. I’ll split this into two cases.
. In the non-Hermitian case, it doesn’t give the eigenvectors, but those can be more easily computed afterward. I’ll split this into two cases.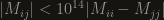
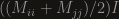 from our 2×2 matrix, since we’re only interested in its (pseudo-)eigenvectors
from our 2×2 matrix, since we’re only interested in its (pseudo-)eigenvectors  can be diagonalized using the same eigenvectors. That basically means that adding/subtracting multiples of
can be diagonalized using the same eigenvectors. That basically means that adding/subtracting multiples of 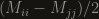 , which also doesn’t change the (pseudo-)eigenvectors. This gives us
, which also doesn’t change the (pseudo-)eigenvectors. This gives us![\left[\begin{array}{cc} 1 & \frac{2M_{ij}}{M_{ii}-M_{jj}} \\ \frac{2M_{ji}}{M_{ii}-M_{jj}} & -1\end{array}\right]](https://s0.wp.com/latex.php?latex=%5Cleft%5B%5Cbegin%7Barray%7D%7Bcc%7D+1+%26+%5Cfrac%7B2M_%7Bij%7D%7D%7BM_%7Bii%7D-M_%7Bjj%7D%7D+%5C%5C+%5Cfrac%7B2M_%7Bji%7D%7D%7BM_%7Bii%7D-M_%7Bjj%7D%7D+%26+-1%5Cend%7Barray%7D%5Cright%5D&bg=161410&fg=999999&s=0&c=20201002)
![\left[\begin{array}{cc} 1 & b \\ a & -1\end{array}\right]](https://s0.wp.com/latex.php?latex=%5Cleft%5B%5Cbegin%7Barray%7D%7Bcc%7D+1+%26+b+%5C%5C+a+%26+-1%5Cend%7Barray%7D%5Cright%5D&bg=161410&fg=999999&s=0&c=20201002)
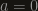 by multiplying by a unitary matrix
by multiplying by a unitary matrix  on the right, a bit of trial and error can give you that
on the right, a bit of trial and error can give you that![V_{\rm sub} = L^{-1}\left[\begin{array}{cc} 1+\sqrt{1+ab} & -a^* \\ a & 1+\sqrt{1+ab}^*\end{array}\right] \\ L=\sqrt{|a|^2 + |1+\sqrt{1+ab}|^2}](https://s0.wp.com/latex.php?latex=V_%7B%5Crm+sub%7D+%3D+L%5E%7B-1%7D%5Cleft%5B%5Cbegin%7Barray%7D%7Bcc%7D+1%2B%5Csqrt%7B1%2Bab%7D+%26+-a%5E%2A+%5C%5C+a+%26+1%2B%5Csqrt%7B1%2Bab%7D%5E%2A%5Cend%7Barray%7D%5Cright%5D+%5C%5C+L%3D%5Csqrt%7B%7Ca%7C%5E2+%2B+%7C1%2B%5Csqrt%7B1%2Bab%7D%7C%5E2%7D&bg=161410&fg=999999&s=0&c=20201002)
 and confirming that the lower off-diagonal element is zero. If
and confirming that the lower off-diagonal element is zero. If  is Hermitian, both off-diagonal elements should be zero. Case 1 complete.
is Hermitian, both off-diagonal elements should be zero. Case 1 complete.
![\left[\begin{array}{cc} 0 & b \\ a & 0\end{array}\right]](https://s0.wp.com/latex.php?latex=%5Cleft%5B%5Cbegin%7Barray%7D%7Bcc%7D+0+%26+b+%5C%5C+a+%26+0%5Cend%7Barray%7D%5Cright%5D&bg=161410&fg=999999&s=0&c=20201002)
![V=L^{-1} \left[ \begin{array}{cc} \sqrt{b} & -\sqrt{a}^* \\ \sqrt{a} & \sqrt{b}^* \end{array} \right] \\ L=\sqrt{|a|+|b|}](https://s0.wp.com/latex.php?latex=V%3DL%5E%7B-1%7D+%5Cleft%5B+%5Cbegin%7Barray%7D%7Bcc%7D+%5Csqrt%7Bb%7D+%26+-%5Csqrt%7Ba%7D%5E%2A+%5C%5C+%5Csqrt%7Ba%7D+%26+%5Csqrt%7Bb%7D%5E%2A+%5Cend%7Barray%7D+%5Cright%5D+%5C%5C+L%3D%5Csqrt%7B%7Ca%7C%2B%7Cb%7C%7D&bg=161410&fg=999999&s=0&c=20201002)
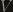 . I temporarily ignored the restriction of having unit vectors and set both of those components to 1, but didn’t ignore the restriction of having the two vectors being complex orthogonal (i.e.
. I temporarily ignored the restriction of having unit vectors and set both of those components to 1, but didn’t ignore the restriction of having the two vectors being complex orthogonal (i.e.  ), giving me
), giving me![\left[\begin{array}{cc} x^* & 1 \\ -x^{-1} & 1\end{array}\right]\left[\begin{array}{cc} 1 & b \\ a & -1\end{array}\right]\left[\begin{array}{cc} x & -x^{-1*} \\ 1 & 1\end{array}\right]=\left[\begin{array}{cc} ... & ... \\ ax-2-bx^{-1} & ...\end{array}\right]](https://s0.wp.com/latex.php?latex=%5Cleft%5B%5Cbegin%7Barray%7D%7Bcc%7D+x%5E%2A+%26+1+%5C%5C+-x%5E%7B-1%7D+%26+1%5Cend%7Barray%7D%5Cright%5D%5Cleft%5B%5Cbegin%7Barray%7D%7Bcc%7D+1+%26+b+%5C%5C+a+%26+-1%5Cend%7Barray%7D%5Cright%5D%5Cleft%5B%5Cbegin%7Barray%7D%7Bcc%7D+x+%26+-x%5E%7B-1%2A%7D+%5C%5C+1+%26+1%5Cend%7Barray%7D%5Cright%5D%3D%5Cleft%5B%5Cbegin%7Barray%7D%7Bcc%7D+...+%26+...+%5C%5C+ax-2-bx%5E%7B-1%7D+%26+...%5Cend%7Barray%7D%5Cright%5D&bg=161410&fg=999999&s=0&c=20201002)

 , and the other by
, and the other by  . Then I just normalize them both (they happened to be the same length,
. Then I just normalize them both (they happened to be the same length,  ), and that’s the solution above. I did the same for case 2, only it was even simpler. Easy… it just took a weekend to figure out what the easy way was.
), and that’s the solution above. I did the same for case 2, only it was even simpler. Easy… it just took a weekend to figure out what the easy way was.





 ). For the GPU, with groups of 32 threads (called warps) sharing an instruction pointer, they must wait 82.8% of the time. This would be another factor of 1.46 (i.e. 82.8%/56.8%), but not all of the time is spent on that branch, so without knowing the breakdown of which parts took how long, one can’t be sure how much it contributes.
). For the GPU, with groups of 32 threads (called warps) sharing an instruction pointer, they must wait 82.8% of the time. This would be another factor of 1.46 (i.e. 82.8%/56.8%), but not all of the time is spent on that branch, so without knowing the breakdown of which parts took how long, one can’t be sure how much it contributes.![1-\frac{1}{\sqrt[k]{2}}\approx\frac{\ln 2}{k}](https://s0.wp.com/latex.php?latex=1-%5Cfrac%7B1%7D%7B%5Csqrt%5Bk%5D%7B2%7D%7D%5Capprox%5Cfrac%7B%5Cln+2%7D%7Bk%7D&bg=161410&fg=999999&s=0&c=20201002)
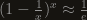 for large x.
for large x.![1-\frac{1}{x} \approx \frac{1}{\sqrt[x]{e}}](https://s0.wp.com/latex.php?latex=1-%5Cfrac%7B1%7D%7Bx%7D+%5Capprox+%5Cfrac%7B1%7D%7B%5Csqrt%5Bx%5D%7Be%7D%7D&bg=161410&fg=999999&s=0&c=20201002)
![1-\frac{1}{\sqrt[x]{e}} \approx \frac{1}{x}](https://s0.wp.com/latex.php?latex=1-%5Cfrac%7B1%7D%7B%5Csqrt%5Bx%5D%7Be%7D%7D+%5Capprox+%5Cfrac%7B1%7D%7Bx%7D&bg=161410&fg=999999&s=0&c=20201002)
![1-\frac{1}{\sqrt[k]{e^{\ln 2}}} \approx \frac{\ln 2}{k}; x = \frac{k}{\ln 2}](https://s0.wp.com/latex.php?latex=1-%5Cfrac%7B1%7D%7B%5Csqrt%5Bk%5D%7Be%5E%7B%5Cln+2%7D%7D%7D+%5Capprox+%5Cfrac%7B%5Cln+2%7D%7Bk%7D%3B+x+%3D+%5Cfrac%7Bk%7D%7B%5Cln+2%7D&bg=161410&fg=999999&s=0&c=20201002)
![1-\frac{1}{\sqrt[k]{2}} \approx \frac{\ln 2}{k}](https://s0.wp.com/latex.php?latex=1-%5Cfrac%7B1%7D%7B%5Csqrt%5Bk%5D%7B2%7D%7D+%5Capprox+%5Cfrac%7B%5Cln+2%7D%7Bk%7D&bg=161410&fg=999999&s=0&c=20201002)
![\sqrt[k]{2}\approx\frac{k}{k-\ln 2}](https://s0.wp.com/latex.php?latex=%5Csqrt%5Bk%5D%7B2%7D%5Capprox%5Cfrac%7Bk%7D%7Bk-%5Cln+2%7D&bg=161410&fg=999999&s=0&c=20201002)

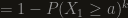

 and solve for it:
and solve for it:
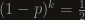
![p = 1-\frac{1}{\sqrt[k]{2}}](https://s0.wp.com/latex.php?latex=p+%3D+1-%5Cfrac%7B1%7D%7B%5Csqrt%5Bk%5D%7B2%7D%7D&bg=161410&fg=999999&s=0&c=20201002)
 . So, as long as we can find the value a at percentile p of the original distribution, we’ve found the median of this distribution of the minimum. Weird stuff.
. So, as long as we can find the value a at percentile p of the original distribution, we’ve found the median of this distribution of the minimum. Weird stuff.
